Doç. Dr. Gökşen Çapar
Ankara Üniversitesi Su Yönetimi Enstitüsü
“İstatistiki düşünme, bir gün okur
yazarlık kadar gerekli olacaktır.”
Belirli bir amaç için;
verilerin toplanması
sınıflandırılması
çözümlenmesi
sonuçlarının yorumlanması
esasına dayanır.
Tablo ve grafiklerle özetleme
Sonuçları yorumlama
Sonuçların güven derecelerini açıklama
Örneklerden elde edilen sonuçları kitle için genelleme
Özellikler arasındaki ilişkiyi araştırma
Çeşitli konularda geleceğe ilişkin tahmin yapma
Deney düzenleme
Gözlem
Bir değişken herhangi bir aralıkta veya
sonsuzlukta birden fazla değer alabilen
miktara verilen isimdir.
Örneğin nüfus bir değişkendir çünkü ne
sabittir ne de değişmezdir; değeri zamanla
değişebilir.
İşsizlik oranı bir değişkendir çünkü %0 ile
%100 arasında herhangi bir değer alabilir.
Rassal değişken (random variable) her
incelendiğinde değişen bilinmez bir değer
olarak düşünülebilir.
Rassal bir değişken ya ayrık (discrete) ya
da sürekli (continuous) olabilir.
Bir değişkenin olası değerleri zıplamalar
ya da keskin aralar içeriyorsa bu değişken
ayrık bir değişkendir. Örneğin, nüfus ayrık
bir değişkendir; çünkü değeri her zaman
tam sayı olarak ölçülür: 1, 2, 3…
Değişkenin olası değerleri zıplamalar ya
da keskin aralar içermiyorsa bu değişken
sürekli bir değişkendir.
Örneğin, sudaki sülfat konsantrasyonu
sürekli değişkendir, çünkü tam birimlerle
ölçülmesi gerekmez: 30.3 mg/L, gibi.
Betimleyici (descriptive) istatistik; toplanmış
verilerin özetlenmesi veya açıklanması amacıyla
kullanılır.
Çıkarımsal (inferential) istatistik; verilerdeki
örtüşmelerin, gözlemlerdeki rassallığı ve belirsizliği
göze alacak şekilde, üzerinde çalışılan evren veya
süreç hakkında sonuç çıkarma amacıyla
modellenmesidir.
Betimleyici istatistikler (descriptive statistics)
bir veri koleksiyonunun özelliklerini nicel
(quantitative) terimlerle açıklamak için
kullanılır.
Frekans dağılımı (frequency distribution),
merkezi eğilim (central tendency), saçılım
(dispersion), birliktelik (association), vb.
Verideki örtüşmeleri modellemek için kullanılır, olasılığı
göze alır ve daha büyük bir istatistiksel yığın hakkında sonuç
çıkarır.
Bu sonuçlar, evet/hayır şeklinde cevaplar olabileceği gibi
(hipotez testi), sayısal özelliklerin tahmin edilmesi
(istatistiksel tahmin) gelecekteki değerlerin öngörülmesi
(istatistiksel öngörü), veriler arasındaki doğrusal ilişkinin
yorumlanması (korelasyon), veya bu ilişkilerin modellenmesi
(regresyon analizi) şeklinde olur.
Diğer belli başlı matematiksel modelleme teknikleri
varyanslar analizi ANOVA, zaman serisi ve veri
madenciliğidir.
Basit bir tanımla, veri madenciliği, büyük
ölçekli veriler arasından bilgiye
ulaşma, bilgiyi madenleme işidir.
Bir anlamda büyük veri yığınları içerisinden
gelecekle ilgili tahminde bulunabilmemizi
sağlayabilecek bağıntıların bilgisayar programı
kullanarak aranmasıdır.
Veritabanlarında bilgi madenciliği (knowledge
mining from databases) de denebilir.
Peter Drucker is an Australian-American author (1909-2005)
Göstergelerle Bilgi Yönetimi
Bilgi Fazlalığı
İstatistiğin bir probleme uygulanmasında önce üzerinde
çalışılan süreç veya evren ele alınır.
Evren bir ülkedeki insanların nüfusu, kayadaki kristal miktarı
veya sudaki kirliliğe neden bir maddenin miktarı olabilir.
Pratik nedenlerden ötürü, bütün evren hakkında veri
toplamak yerine genelde evrenden seçilen bir altküme
(örnek veya örneklem) üzerinde çalışılır.
Örnek hakkındaki veri deney veya gözlem yoluyla elde edilir.
Bundan sonra veri istatistiksel analize tâbi tutulur. Bunun iki
amacı vardır: açıklama (betimleme) ve sonuç çıkartma.
Parametre
(nehirdeki su sıcaklığı)
İstatistik
(örnekteki su sıcaklığı)
Her veri seti belirli değerlerin ne kadar sıklıkta
görüldüğüne göre açıklanabilir.
İstatistikte, frekans dağılımı bir veya birden
fazla değişkenin aldığı değerlerin sıklıklarının
tablolaştırılarak sunulmasıdır.
Tek değişkenli frekans dağılımları (univariate
frequency distributions) genellikle her bir değerin
ne kadar sıklıkla bulunduğunu gösterir.
Bir frekans dağılımı isteğe göre gruplanabilir ya da
gruplanmayabilir.
Küçük veri setleri için gruplanmamış frekans
dağılımları daha uygunken büyük veri setleri için
gruplanmış frekans dağılımları daha uygundur.
Merkezi eğilim, istatistikte nicel (sayısal) bir
verinin “merkezi bir değer” etrafında toplanma
yatkınlığını ölçme işlemidir.
Ortalama (mean)
Orta değer (median)
Tepe değer (mode)
Aritmetik ortalama (mean) bir veri setindeki bütün
elemanların toplamının eleman sayısına bölümüyle
elde edilir.
Eğer veri seti bir istatistiki popülasyonsa,
ortalama popülasyon ortalaması (population mean)
olarak adlandırılır.
Eğer veri seti bir örnek (sample) ise,
ortalama örneklem ortalaması (sample mean)
olarak adlandırılır.
Eğer bir dizi veriyi
X = (x1, x2, …, xn)
şeklinde ifade edecek olursak örneklem
ortalaması x̄ olarak gösterilir.
Bir Yunan alfabesi harfi olan μ ise komple popülasyonun
ortalamasını gösterir.
Bir örneklemin ya da
popülasyonun daha büyük
değerlere sahip yarısını
daha küçük değerlere
sahip öbür yarısından
ayırmak için kullanılan
sayısal bir değerdir.
Sınırlı bir numaralar serisinin orta değeri,
serinin küçükten büyüye sıralandıktan sonra
tam ortasındaki değerin alınmasıyla
bulunabilir. Eğer bu seri çift sayıda değer
içeriyorsa o zaman orta kısımda bir değer
bulunmayacaktır. Bu durumda ortadaki iki
değerin ortalaması orta değer olarak alınır.
Örneğin sudaki sülfat konsantrasyonu artan şekilde
sıralayalım:
67.05, 66.89, 67.45, 67.45, 68.39, 68.39, 70.10
Tepe değer bir veri
listesinde en çok
gözlemlenen değerdir.
Tepe değer tek bir değer
olmak zorunda değildir; aynı
sıklığa sahip birden fazla
değer olabilir.
Sülfat konsantrasyonunu artan şekilde sıralayalım,
67.05, 66.89, 67.45, 67.45, 68.39, 68.39, 70.10
En çok gözlemlenen iki tepe değer vardır:
67.45 ve 68.39.
Bu yüzden bu veri setinin tepe değeri tek değil iki tanedir. Bu veri
setine çift tepe değerli (bimodal) denir.
Bir popülasyon ya da örneğin bir, iki, veya ikiden fazla tepe değeri
olabilir.
İstatistiki saçılım (ayrıca istatistiki değişkenlik, veya
çeşitlilik) olasılık dağılımındaki dağınıklık (yayılım) olarak
adlandırılır.
Veri setindeki değerlerin ne kadar dağınık olduğunu
ölçümlemede kullanılır.
Yaygın olarak kullanılan istatistiki saçılım ölçümü şunlardır:
Varyans (variance)
Standart Sapma (standard deviation)
İstatistikte varyans, rassal bir değişkenin veya
dağılımın her bir değerinin ortalama değerden
farkının karesinin ortalaması olarak ifade edilir.
Varyans, verinin ortalama değerden ne kadar
saptığının bir ölçüsüdür.
Eğer rassal bir değişken olan X’in beklenen değeri
(expected value = mean) E[X]=μ ise, X’in varyansı:
İstatistikte, rassal bir değişkenin veya dağılımın standart
sapması o değişkenin varyansının kareköküne eşittir.
Yani, standart sapma σ (sigma) (X − μ)2 değerlerinin
ortalamasının kareköküdür.
İki değişkenli istatistik (bivariate statistics) iki
değişkenin, birinin diğerine sebep olduğunu ima
etmeksizin, birbirleriyle nasıl ilişkili olduklarını
incelemek için kullanılabilir.
Çok değişkenli istatistik (multivariate
statistics) ikiden fazla değişkenin, birinin
diğerlerine sebep olduğunu ima etmeksiniz,
birbirleriyle nasıl bir ilişki içerisinde olduğunu
incelemek için kullanılabilir.
İki değişkenli ve çok değişkenli istatistiklerin
ölçülmesinde yaygındır:
Korelasyon Katsayısı (correlation coefficient)
İki rassal değişken arasındaki doğrusal ilişkinin
yönünü ve gücünü belirtir.
Korelasyon katsasının değeri -1 ile +1 arasında (-1
ve +1 de dahil) bir değerdir.
0 ise X ve Y ilişkisizdir (uncorrelated)
1 ise X ve Y doğru yönde tamamen ilişkilidir. Biri
artarken diğeri de kesinlikle artar veya biri azalırken
diğeri de kesinlikle azalır.
-1 ise X ve Y ters yönde tamamen ilişkilidir. Biri
artarken diğeri kesinlikle azalır.
Kullanmak; Riskli !
Kullanmamak; Cahillik!
Dondurma boğulmaya neden olmaz.
Boğulma vakaları da daha fazla dondurma yemeye sebep
olmaz.
Yaz mevsiminde sıcaklık artınca insanlar daha fazla
dondurma alır.
Havuz ve denizde daha fazla zaman geçirirler.
Dondurma tüketimi ve boğulma vakaları arasında
korelasyon olabilir, ancak birisi diğerine sebep olmaz.
Nedensellik var mı?
A, B’ye sebep olur mu?
Büyük ayaklar yazım kuralları konusunda yeteneği
artırırsa, beslenme ile ilgili bir sebep mi var?
Ayakkabılarla mı ilgili?
Ayak büyüklüğü genetik olabilir.
Doğaya karşı beslenme??
B mi A’ya sebep oluyor? Belki de yazım kuralları yeteneği
hormonal değişimlere neden oluyor? Akademik bir başarı için
harcanan süre, açlığı, gıda tüketimini ve ayak numarasını
artırıyordur?
Bir başka görüş; çocukların ayaklarının, çocukların yaşıyla
birlikte arttığını söylüyor. 8 yaşında bir çocuğun ayakları, 5
yaşındaki bir çocuktan büyüktür. 15 yaşındakinin ayağı da 8
yaşındakinden büyüktür. Çocuklar büyüdükçe, küçüklere göre
yazım kurallarını daha iyi öğrenirler.
Ayak numarası ve yazım kuralları yeteneği arasında korelasyon
vardır, ancak birisi diğerine sebep olmaz.
Bir parametre (parameter) popülasyonu betimleyen
bir sayıdır. Bir parametre sabit bir sayıdır, ama
pratikte bu değeri bilmeyiz.
İstatistik (statistic) ise bir örneklemi betimleyen bir
sayıdır. Bir istatistiğin değeri örneklemden elde
edilir; fakat aynı popülasyonun farklı örneklemleri
için farklı değerler elde edilebilir.
İstatistiği (statistic) sıklıkla bilinmeyen bir
parametreyi hesaplamak için kullanırız.
Örneklem sayısı=100
ÇO1= 10 mg/L
ÇO2= 4 mg/L
ÇO3= 5 mg/L
…
ÇO ort= 5mg/L
Tüm Kızılırmak nehrindeki ortalama ÇO nedir?
Aldığımız 100 örnekteki ortalama ÇO=5 mg/L
Bir 100 örnek daha alalım, ortalama ÇO= 7 mg/L
Bir tane daha, ortalama ÇO=3 mg/L
Ne kadar yakın gerçek değere?
Ne kadar çok örnekleme yaparsak, gerçek değere o kadar
yaklaşırız. Ancak bunun kısıtları var; zaman, maliyet, iş gücü vb.
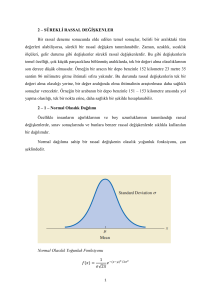
Normal olarak
adlandırılan eğriler
simetriktir, tepe
noktalıdır ve çan
şeklindedir.
Ortalama değer (mean) simetrik bir eğrinin tam ortasındaki
değerdir ve bu değer aynı zamanda orta değerdir (median).
Standart sapma ise normal eğrinin ne kadar yayıldığını
gösterir.
Ortalaması 0 olan ve standart sapması 1 olan bir normal dağılım çeşididir.
Eğer bir değişken olan X in ortalaması m ve standart sapması s is ve normal dağılıma
sahipse, standardize edilmiş olan
değişkeni standart normal dağılıma sahiptir.
ÇO=4 mg/L’den düşük olan örneklerin oranı nedir?
X değişkenini standart normal z skoruna dönüştürmek için
normalleştirmeyi bulmak istediğimiz değerden (4 mg/L)
ortalama değeri (5 mg/L) çıkartıp sonucu standart
sapmaya (1,34 mg/L) bölerek yaparız:
ÇO ort=5 mg/L
Standart sapma=1,34 mg/L
Z= (4 - 5) / 1,34= - 0,73
Z Tablosundan -0.73 değerine bakacak olursak
değerin 0.2327 olduğunu görürüz.
Bu z değerinin solunda kalan (yani bu
değerden küçük olan) değerlerin toplam
dağılım içindeki oranı 0.2327.
Yani Kızılırmak nehrindeki ortalama ÇO
derişiminin 4 mg/L’den düşük olma oranı
%23.27’dir.
Teşekkürler !