VERİLERİN DÜZENLENMESİ VE
ORGANİZASYONU
İstatistik analizlere başlamadan önce yapılması
gereken ilk iş verilerin düzenlenmesi olmalıdır.
İstatistiksel çalışmalarda pek çok analizi
uygulayabilmek için verilerin dağılımının normal
yada normale yakın olması gerekir. Verilerin
dağılımı; histogram, saplı kutu grafiği, detrented
normallik grafiği ve dal yaprak gibi grafikler
kullanılarak gösterilebilir. Ayrıca Kolmogorav
Smirnow ve Shapiro Wilks testleride kullanılabilir.
Örnek Uygulama: Bağımlı değişken kimya puanı
ve bağımsız değişken bölüm kullanılarak verilerin
dağılımının gösterimi
Analyze
Descriptive Statistics
Explore
Aşağıdaki ekran görülür
Bağımlı
değişken
1
2
Aşağıdaki ekran açılır
işaretlenir
basılır
Alttaki işleme geçiniz
işaretle
işaretle
Ve…. Continue butonuna basılır
Artık çıktıları yorumlamaya geçebiliriz
Şimdi öğrendiklerimizi uygulayalım
Tanımlayıcı istatistikler
Ortalama
Güven
aralığı
Ortanca
Standart
sapma
Çarpıklık
Basıklık
Mean (Ortalama): Gözlem sonuçlarının toplamının
gözlem sayısına bölümüdür.
Her bir gözlem değerinin ortalamadan sapmalarının
toplamı gözlem sayısına bölünürse ve karekökü
alınırsa Standart Sapma bulunur.
Standart sapmanın karesi varyansı verir.
Tahmini yapılacak büyüklüğün arasında kalacağı
alanın hesaplanmasına Güven Aralığı denir.
Seriyi iki eşit parçaya bölen değer Ortanca
(Medyan) dır.
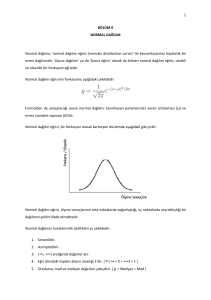
İstatistik çalışmalarında en yaygın kullanılan
dağılım Normal Dağılımdır. Normal dağılım
simetriktir. Şekli çan eğrisine benzer. Simetrik bir
dağılımın tepe değeri (Mod), ortancası (Medyan) ve
Ortalaması birbirine eşittir.
Basıklık (Kurtosis) ve Çarpıklık (Skewness)
değerleri verilerin normal dağılım gösterip
göstermediğini ifade eder.
Çarpıklık veri dağılımının normalden uzaklaşarak
sağa ve ya sola doğru meyleden yamuk bir şekil
almasını ifade eden bir kavramdır. Normal bir
dağılımda çarpıklık katsayısı “sıfır” olacaktır.
Çarpıklık arttıkça mod ve ortalama birbirinden
uzaklaşır.
Çarpıklık katsayısı – sonsuz ile + sonsuz
arasında değerler alabilmektedir. Pozitif ve
Negatif olmak üzere iki tir çarpıklıktan söz
edilebilir. Eğer ortalama medyandan küçük ise
dağılım sola (negatif) çarpık olur. Eğer ortalama
medyandan büyük ise dağılım sağa (pozitif)
çarpık olur. Çarpıklık ölçüsü ± 3 (±2 de olabilir)
aralığında değerler alması durumunda normal
kabul edilmektedir.
Analiz çıktısından elde edilen tanımlayıcı
istatistikler tablosundaki Skewnwss’e ait statistic
değeri Std. Error değerine bölünerek bulunan
değer çarpıklık değeridir. Bu değer % 5
anlamlılık düzeyinde +1,96 ve -1,96 değerleri
arasında ise veriler normale yakındır denilebilir.
Bu değerin pozitif çıkması verilerin sağa çarpık,
negatif çıkması ise sola çarpık olduğunu
gösterir.
Basıklık (Kurtosis) normal dağılım eğrisinin ne
kadar dik ve ya basık olduğunu gösterir. Tam çan
eğrisinin basıklık katsayısı “sıfır”dır. Basıklık
katsayısı pozitif ise, eğri normale göre daha diktir.
Negatif ise normale göre daha basıktır. Analiz
çıktısından elde edilen tanımlayıcı istatistikler
tablosundaki Kurtosis’e ait statistic değeri Std. Error
değerine bölünerek bulunan değer % 5 anlamlılık
düzeyinde +1,96 ve -1,96 değerleri arasında ise dik
olmadığı söylenebilir.
Histogram
Historam çizimleri
verilerin ne kadar
sıklıkla tekrar
edildiğini gösteren
grafiklerdir. Yandaki
histogram eğrisine
bakıldığında eğrinin
tam simetrik olmadığı
sola çarpık olduğu
görülmektedir.
Bu grafikte verilerin
gözlenen ve beklenen
değerleri gösterilir. Eğer
üzerinde çalışılan
örneklem normal
dağılıma sahip ise
değerlerin bir doğru
üzerinde ve ya etrafında
toplanması gerekir.
Yandaki şekilde veriler bir
doğru üzerinde
toplandığı için veri
grubunun normale yakın
olduğunu söğleyebiliriz.
Normal İhtimal Grafiği
Bir veri grubu normal
dağılım gösteriyorsa
değerlerin sıfır
çizgisinden
sapmalarının gösterildiği
bu grafikte beklenen
noktaların dikey
eksendeki “0” dan
çizilen yatay çizgi
etrafında bir fonksiyon
biçimini oluşturmadan,
rasgele dağılması
beklenir.
Trendsiz normallik grafiği
Bu veriler normale yakın
dağılmıştır
Kutu grafiği yüzdeliklere
dayanan tanımlayıcı
istatistikleri kullanır. Şeklin
uzunluğu çeyreklikler
arasındaki aralıktır. Kutu
dağılımın %50’sinin merkezi
eğilimi ve yaygınlığı ile ilgili
bilgi verir. Eğer ortanca çizgisi
merkezin altında ise dağılım
pozitif çarpık, üstünde ise
negatif çarpıktır. Tam ortada
yer alması dağılımın normal
olduğunu göstermektedir.
Saplı kutu grafiği
Sola çarpık (negatif)
dağılımı ifade etmektedir
EKSİK VERİLERİN İNCELENMESİ
Her analizde eksi verilerle karşılaşabiliriz. Bir ankette
kişi soruyu cevapsız bırakabilir… bazı değişkenlerle
ilgili gözlem değerlerine ulaşamayabiliriz…. O halde
Ne yapmamız gerekir?
Bu durumda
Eksik verilerin gözlemlere rasgele mi saçıldığı
yoksa belirgin bir yapı mı oluşturduğu,
Eksik verilerin ne kadar sıklıkla karşımıza
çıktığının araştırılması gerekir.
Eksik veriye yol açan gözlemleri veri grubundan
çıkarma yoluna gitmeyiniz. Gözlem sayınız önemli
derecede etkilenebilir.
O zaman….
Veriye yeni gözlem değerleri eklenebilir,
Verideki eksik değerler çeşitli
yaklaşımlarla giderilmeye çalışılır.
istatistiksel
Eksik verileri incelemek için
Seçilir
İşaretlenince
Missing Value
Analysis
penceresi
açılır.
İşaretlenir
Bütün değişkenler Quantitative Variables
bölümüne aktarılır.
2.Adım
3.Adım
1. Adım; çünkü
gözlem sayısı
eksik gözlem
sayısından daha
fazladır.
2. Adım (Patterns)
İşaretlenir
Değişkenler
aktarılır
Seçilir
3. Adım (Descriptives)
Hepsi
işaretlenir
Seçilir
En son pencerede “OK” işaretlendikten sonra
analiz çıkıları ekranı gelir.
Buraya kadar yaptığımız işlemler sonucunda elde
ettiğimiz tablolardan eksik verilerin yapısı,
rasgelelik olup olmadığı, eksik verilerin toplam
verilere etkisi tespit edilebilir.
Separate Variance t Test
Rasgelelik durumu t testi tablosundaki P(2-tail)
Değeri %5 den büyük ise eksik verilerde rasgelelik
vardır.
Listwise Correlation
Rasgelelik durumu korelasyon matrisindeki
korelasyon değerleri yüksek değil ise eksik
verilerde rasgelelik vardır.
Summary of Estimated Mean
Tahmini ortalamalar tablosundaki Listwise
bölümünde sadece tam olan gözlemlere ait
ortalamalar, All values bölümünde ise eksik
verilerin olduğu gözlemlerde dahil tüm
gözlemlere ait ortalamalar hesaplanmıştır.
Bu değerlerin karşılaştırılması ile farklılık
olup olmadığını ve eksik verilerde rasgelelik
olup olmadığı anlaşılabilir.
Data Patterns (all cases)
Eksik ve tam gözlem sayıları tablosundan
eksik verilerin sayısı ve eksik verinin hangi
gözlemin
hangi
değişkeninde
olduğu
görülebilir. Bu tabloda eksik veriler “S” ile
gösterilir.
Missing Patterns (cases with missing values)
Eksik veri yapısı tablosu ve Tabulated Pattern
tablolaştırılmış eksik veri yapıları tablosundan
eksik verilerin yapısı, sayısı ve tam gözlem
sayısını etkileme durumunu inceleyebiliriz.
Bunları bir örnek üzerinde görelim
EKSİK VERİLERİN TAMAMLANMASI
Burada eksik verileri çıkartmadan nasıl analize
koyabiliriz? Sorusunun cevabı arayacağız.
Transform
Replace Missing
Values
Komutlarını uygulayınız…..
Aşağıdaki diyalog penceresi açılır.
Method kısmından herhangi bir metod seçilir
sonra tüm değişkenler New Variable(s) kısmına
aktarılır. Ve “OK” butonuna basılır.
Eksik değerin altındaki
ve üstündeki tam
verilerin ortalamasını
alarak eksik verinin
yerine koyar
Eksik değerin
altındaki ve üstündeki
tam verilerden
yararlanarak bir
medyan değeri
hesaplar eksik verinin
yerine koyar
Serinin ortalamasını
alarak eksik verilerin
yerine koyar
Eksik değerin
altındaki ve
üstündeki tam
veriler kullanılır
Mevcut seriler 1’den n’e
kadar ölçeklendirilmiş bir
endeks değişkeninde eksik
veriler öngörülen
değerlerine göre yerleştirilir
Eksik veriler tamamlanmadan önceki durum
Eksik veriler tamamlandıktan sonraki durum